Backups & Storage
HDD shortage 2026: how to buy recertified drives safely
The HDD market in 2026 is broken. Western Digital's CEO publicly said WD is 'pretty much sold out for calendar 2026' with firm POs into 2027-2028; HDD prices are up 46% since September 2025; lead times on 18TB+ stretched to 10+ weeks; Toshiba is refunding warranty claims at original purchase price instead of replacing drives (because replacement stock doesn't exist). On top of that, the January 2025 Seagate scandal — drives sold as 'new' but with 15,000-50,000 hours on the SMART FARM log — broke buyer trust in even certified-partner channels. For home operators building or expanding a NAS, recertified and refurbished drives are now the default play, not the budget option. The trick is buying from the right vendor and verifying every drive on arrival.
The on-arrival verification commands, captured from a real Unraid box
Reference images and diagrams. Click any image to view full resolution.
Who this is for
Home operators building or expanding a NAS in 2026 hitting the WD/Seagate shortage. Looking at 16-22TB drives, finding 'out of stock' everywhere, and weighing recertified vendors against the Seagate FARM scandal risk.
Outcome
A working buying playbook: which recertified vendor to use, what drives to look for, the inspection runbook on arrival, and how to handle RMA inside the 10-30 day vendor window when burn-in fails.
Required inputs
- A NAS or test machine with available SATA ports for burn-in (or a USB-to-SATA dock).
- A workstation with `smartctl` 7.4+ installed (Linux easiest; Windows via Cygwin or WSL).
- Enough time budget for the 5-7 day burn-in per drive (parallel drives shorten total time but not per-drive time).
- Budget decision: full retail new vs recertified (~25-40% savings) vs eBay datacenter pull (deeper but higher variance — community lore says ~50%, treat as directional).
Step-by-step procedure
Pick the vendor based on your priorities
Do: Most operators: ServerPartDeals (SPD) or GoHardDrive (GHD) — multi-year warranty + community-verified grading. Lowest risk + budget: WD/Seagate factory recert direct from manufacturer (limited stock). Backup tier only: eBay datacenter pulls (high variance). Avoid Amazon Renewed for HDDs.
Expected result: Vendor chosen; order placed with documented warranty period + return policy.
If not: If your priority is warranty-that-matters-in-2026, prefer SPD/GHD's multi-year vendor warranty over a manufacturer warranty. Note the 2026 Toshiba situation: its 'refund in lieu of replacement' clause is longstanding warranty language, but Toshiba is now *enforcing* it (no stock) and refunding at the original price — below current replacement cost — so a replace-not-refund vendor warranty is worth more right now.
Inspect every drive on arrival before adding to production
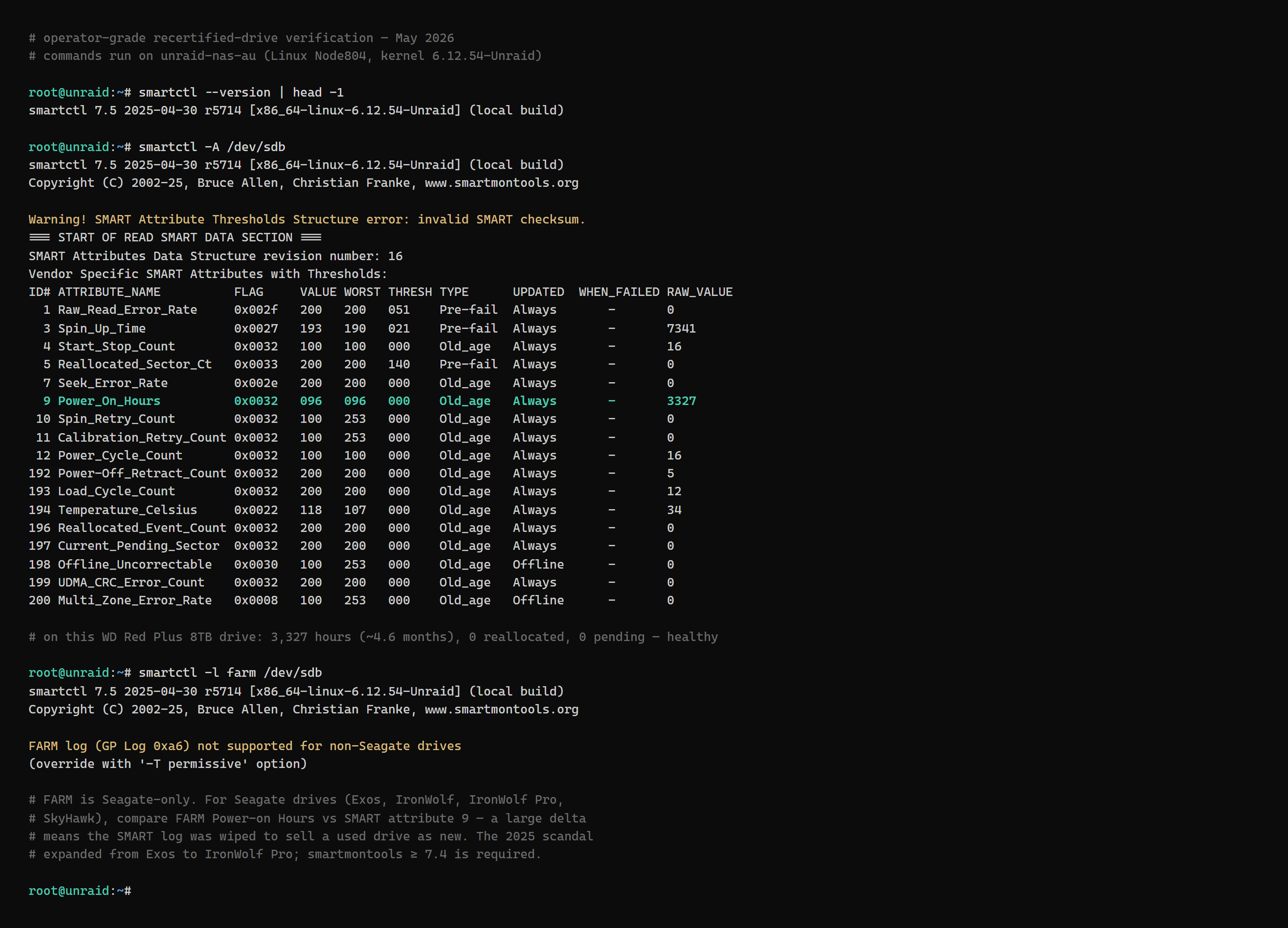
Do: Pull drive out of antistatic; visually inspect (no PCB damage, no oily contamination). Connect to SATA port (test machine, USB dock, or NAS in a temp slot). Run `smartctl -a /dev/sdX` to get baseline.
Expected result: SMART reports: model + serial + firmware visible; Power_On_Hours plausible for vendor's claim (≤ few thousand for recert; 0 for 'new'); Reallocated_Sector_Ct and Current_Pending_Sector at 0.
If not: If reallocated/pending sectors > 0, RMA immediately. If Power_On_Hours wildly above vendor claim, also RMA (Seagate: cross-check FARM in next step).
For Seagate drives: FARM cross-check (the Seagate FARM scandal step)
Do: `smartctl -l farm /dev/sdX` (requires smartmontools 7.4+). Compare FARM's 'Power on Hours' against standard SMART attribute 9.
Expected result: FARM hours ≈ SMART attribute 9 hours (delta < 100 typically). Both consistent with vendor's claim.
If not: Any non-trivial delta = scandal-grade fraud. SMART attribute 9 reset to 0 with FARM showing thousands of hours = the Seagate scandal. RMA immediately with FARM evidence. Multiple retailers including Seagate-certified partners distributed scandal-affected drives.
Run SMART self-tests (short then extended)
Do: `smartctl -t short /dev/sdX`, wait 5 min, then `smartctl -l selftest /dev/sdX`. Then `smartctl -t long /dev/sdX` (4-12 hr per drive depending on size).
Expected result: Both tests complete with 'Completed without error.'
If not: Any read/seek/ECC error in selftest result = RMA. Don't burn-in a drive that's already failing self-test.
Destructive 4-pattern badblocks burn-in (the long one)
Do: `badblocks -b 4096 -wsv -o /root/badblocks-sdX.log /dev/sdX` (use `-b 8192` for >16 TiB drives). Patterns 0xaa, 0x55, 0xff, 0x00. ~24 hr per 8 TB.
Expected result: Log file empty at completion (no bad blocks found).
If not: Any non-empty output = drive has bad blocks. RMA inside the vendor's window (10-30 days from SPD/GHD).
Re-read SMART after burn-in for delta
Do: `smartctl -A /dev/sdX`. Compare attributes to the baseline from step 2: Reallocated_Sector_Ct, Current_Pending_Sector, Offline_Uncorrectable, UDMA_CRC_Error_Count.
Expected result: All four counters unchanged from baseline. Drive accepted.
If not: Any new bad blocks in any of those counters = RMA. Single-digit growth is debatable for production; on a fresh recert, treat as RMA-grade. The burn-in caught a drive that would have failed within 90 days.
Platform-specific final acceptance
Do: Unraid: run the preclear plugin (1-pass post-badblocks is sufficient); add to array as data or parity. TrueNAS Scale: add to a temporary single-disk pool, run `zpool scrub` + 24-hr `fio` workload, destroy temp pool, add to production vdev. Synology DSM 7.3: Storage Manager > Extended SMART + Bad Sector Test, then add to pool. QNAP: HDD Stress Test in Helpdesk, then SMART extended.
Expected result: Platform-specific tests pass; drive goes into production.
If not: If platform-specific tests find issues that the generic burn-in missed (unusual), still RMA — the vendor's burn-in didn't catch this drive's issue.
Commands and settings paths
Baseline SMART check
smartctl -a /dev/sdX
Where: Linux test machine, Unraid console, or TrueNAS Scale shell.
Expected: Reports: model, serial, firmware, Power_On_Hours, Reallocated_Sector_Ct, Current_Pending_Sector, UDMA_CRC_Error_Count, etc.
Failure means: Reallocated/pending > 0 on a 'new' or 'recert' drive = bad drive; RMA before burn-in.
Safe next step: Capture output to file; RMA immediately if criteria fail.
Seagate FARM check (Seagate-only)
smartctl -l farm /dev/sdX
Where: Same as above; requires smartmontools 7.4+.
Expected: FARM Power_On_Hours ≈ SMART attribute 9 hours.
Failure means: Non-trivial delta = Seagate FARM scandal fraud — drive was used heavily before being sold as new.
Safe next step: RMA immediately with FARM evidence; report to Seagate Ethics Helpline if vendor was on Seagate's certified-partner list.
Confirm smartmontools is new enough to read FARM
smartctl --version
Where: The Linux / Unraid / TrueNAS shell you'll inspect drives from.
Expected: Version 7.4 or newer (FARM-log support landed in 7.4; current is 7.5).
Failure means: On 7.3 or older, `smartctl -l farm` won't work and you can't do the Seagate anti-fraud check.
Safe next step: Update smartmontools (or use SeaTools/openSeaChest); don't accept a Seagate recert without the FARM check.
Verify the drive is CMR, not SMR
Decode the model suffix against the vendor CMR/SMR list; heuristic: `smartctl -a /dev/sdX | grep TRIM` — TRIM on a mechanical drive indicates DM-SMR.
Where: Vendor spec page + the inspection shell.
Expected: Model is on the CMR list (enterprise nearline like Exos/Ultrastar/MG, or WD Red Plus/Pro, are CMR).
Failure means: An SMR drive (e.g. WD EFAX) will stall or drop out during a RAID rebuild.
Safe next step: Return it; buy a confirmed-CMR model for any pooled/parity slot.
Check the manufacturer warranty by serial
Seagate seagate.com/support/warranty-and-replacements; WD support-en.wd.com/app/warrantystatusweb; Toshiba US RMA portal (serial from `smartctl -i`)
Where: In a browser, with the drive serial.
Expected: Warranty status + remaining term shown, matching what the vendor claimed.
Failure means: 'Out of warranty' or 'recertified - not covered' means you're relying entirely on the seller's vendor warranty.
Safe next step: Confirm the seller's vendor warranty length/return terms in writing; for recert, that's usually the coverage that matters.
Evidence to record
- Initial `smartctl -a` output saved per drive (baseline).
- For Seagate: `smartctl -l farm` output saved.
- Extended SMART self-test result.
- Badblocks log file (should be empty).
- Post-burn-in `smartctl -A` showing no new bad sectors.
- Vendor order date + RMA window expiration date (so you don't miss the return window).
Common mistakes
- Skipping burn-in to save time, then losing a drive 60 days in — outside the vendor's 10-30 day RMA window.
- Adding a new recertified drive directly to parity without burn-in — when it fails during rebuild stress, the array is at risk.
- Not running the FARM cross-check on Seagate drives — SMART power-on-hours can be reset (the whole 2025 scandal); only `smartctl -l farm` exposes the true hours.
- Buying SMR by accident for a RAID pool — DM-SMR drives stall or drop out during rebuilds. Verify the model is CMR before buying (beware the SATA-TRIM-on-a-mechanical-drive = SMR tell).
- Trusting Amazon Renewed listings for HDDs — repeatedly implicated in fake-new HDD scandals; prefer SPD/GHD/manufacturer-direct with a stated warranty.
- Buying eBay datacenter pulls for primary array slots — high variance, ~10-20% DOA rate; only acceptable for the backup tier.
- Relying on a manufacturer warranty that's been gutted — Toshiba is refunding (at original price) instead of replacing; WD recert is 1yr, Seagate recert 6mo, and MR drives often carry NO mfr warranty. A vendor multi-year warranty usually matters more.
- Buying a whole batch from one seller and one production lot — identical drives from the same lot tend to fail together. Stagger sources/dates.
- Ignoring the Power-On-Hours-vs-FARM delta — a tiny SMART POH with a huge FARM POH is fraud; a large but consistent POH is an honestly-disclosed used drive.
- Not inspecting the recert label / drive condition — a misplaced or scratched recert label, or wear around the screw holes, signals a fraudulent 'new.'
- Forgetting the Power-Disable (P3) pin — modern enterprise SATA drives won't spin up in a legacy backplane without the SATA-to-SATA adapter, and get mistaken for dead.
- Treating RAID as the backup — a bad drive (or a bad batch) becomes data loss without an offsite copy; SMART misses ~23% of failures with no prior warning.
Stop points
- Stop before adding any recertified drive to a parity slot or pool without completing the full inspection + burn-in.
- Stop before the RMA window closes (10-30 days from vendor receipt) — fail any drive that doesn't pass burn-in inside that window.
- Stop before buying high-capacity drives this shortage from a vendor whose return policy is 'manufacturer warranty only' — manufacturer warranties have degraded (Toshiba refunding not replacing) or are effectively no-replace (out of stock).
- Stop before putting a drive in a RAID pool until you've confirmed it's CMR, not SMR — DM-SMR fails rebuilds.
- Stop before buying every drive from one seller and one lot — split sources so a bad batch can't take out enough drives to kill the array during a rebuild.
Last reviewed
2026-05-18
Source-backed checks
HomeTechOps turns official docs and conservative safety rules into a shorter runbook. These links are the source trail for the page direction.
Planning a purchase?
We keep a source-backed, price-free comparison so you can buy once and right. No star ratings, every spec cited.
NAS Drives: WD Red vs IronWolf vs N300 →